Network Automation - Why is it important?

Network Automation - Why is it important?
In the last few years, I’ve seen tremendous interest and increase in the adoption of automation in the networking world. The DevOps philosophies and practices are aiming to break the silos between Operations and Developers to accelerate the deployment of well-defined and well-tested changes. But is this truly necessary in the networking realm? What problem are we trying to solve with automation, and what benefits can you get out of it?
In my professional life, automation has helped me to avoid doing repetitive and monotonous tasks. One of the most annoying jobs I had to do over and over again was deploying or updating firewall rules. Using automation, I’ve managed to reduce the time it takes me to deploy a new firewall rule, up to the point that I don’t even need to think on what commands or in which firewall I need to deploy the rule. I can now quickly deploy a security policy from A to B, and the system will think, prepare and make the changes for me. Deploying automation solutions has allowed me to free up my time to focus on solving more significant problems while also getting more job done.
In this post, I’d like to tell you a few other areas on which network automation can help you.
Consistency makes your network predictable
Sometimes we can overestimate the scope of a change and think – “I’ve done this change 1 million times, this that won’t cause any problems” – to later in the day (or night) ending up causing an outage.
The dreaded Maintenance Window
Let’s imagine you are starting a maintenance window: Your task today is to test 4 x LACP links (2 x 100G each) in 4 different switches and make sure that traffic is not interrupted if one of the links go down. To do this, you are going to shut down one of the links, monitor for 30 minutes and then bring it back.
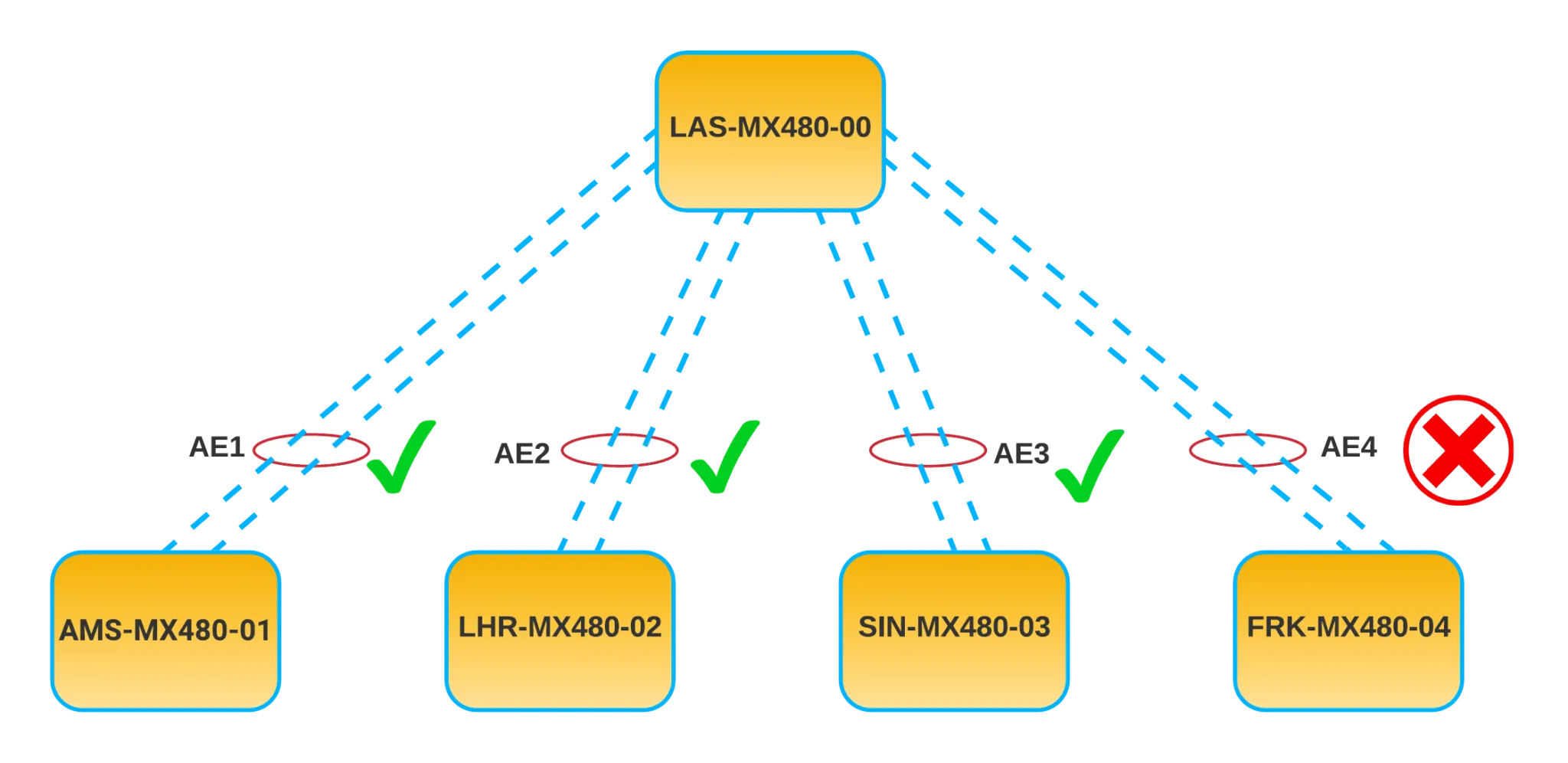 Figure 1 - Maintenance’s Logical Diagram
Figure 1 - Maintenance’s Logical Diagram
You reach the last device, and when shutting down one of the interfaces in FRK-MX480-04, you see that traffic suddenly stops flowing to LAS-MX480-00, so you quickly roll back the change, and the problem disappears. But what happened, how could something like this have gone wrong?
While investigating the root cause of the problem, we start digging into the current configs (Try and see if you can find the culprit!!):
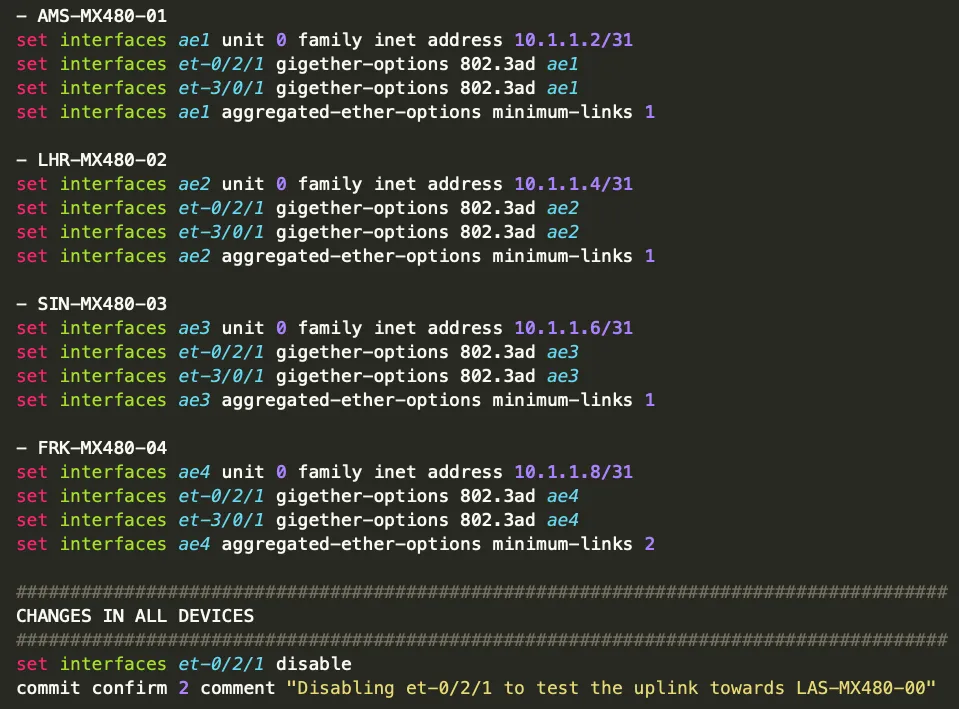 Figure 2 - Maintenance Changes
Figure 2 - Maintenance Changes
In the image above, we notice that FRK-MX480-04 was configured to expect at least two links to be up to mark the AE4 interface as operational but because one of the two interfaces went down, the AE4 link was immediately marked as down and traffic stopped flowing.
With this example, I’m hoping you can appreciate how important it is to keep the consistency of your config to predict the results accurately and ultimately reduce the chances of outages.
Reducing human error
After looking at the root cause of the issue in the previous maintenance, we can conclude that this problem was caused by human error. Let’s reflect for a bit to understand what could have gone better:
- The person doing the change should have spotted this config mismatch before the maintenance.
- This change should have been previously tested in a dev environment which would have replicated the same config available in the live environment and would have caught the problem early without causing any downtime.
- Why was there a mismatch in the configs, was this caused by a lack of a standardised way to configure these interfaces or was it just the case of a simple human error?
- Having to apply commands manually in multiple places is error-prone, and any network engineer could have easily mistyped the interface name and shut down another interface instead.
So, how can we avoid this problem in the future (or at least reduce the likelihood of reoccurrence)?. We can try the following suggestions:
- Create an automation solution that will include:
- A set of tests that will check connectivity to upstream endpoints before and after the change. This requires a solid network observability strategy.
- An automatic rollback feature in case that connectivity is broken after a change has been deployed.
- Create a test environment that replicates the current network segment available in production.
- Testing the change in a dev environment before deploying it to production.
By adding testing, an automated deployment and validations to your workflow, you will be reducing the risks of an outage caused by human-errors, just like the one we saw in our maintenance.
Scale, availability and time to deploy
In our change we only showed five routers, but what if you had to do a similar change in 100s of devices? Would you approach this change the same way? Absolutely NOT!.
It seems a pretty obvious point, but the bigger your network is, the bigger is the need for automation. If you have 1000s of devices in your network and you had a password breach, you would want to update all your devices quickly without having to log into them manually.
Besides the scale, you will need to automate processes and tasks if you want to maintain a high level of availability. Let’s take the example of AWS, as many of us use it to deploy apps.
AWS offers at least four 9s (99.99%) of availability per month when an EC2 is deployed in 2 AZs, and maintaining this level of availability means that you can only afford 4,38 minutes of downtime in a month. If you need to manually log into a device, check why one of you transit links is congested and reroute traffic via another link, this will certainly will take your more than 5 minutes and it will cause a breach of your SLAs.
If you are frequently deploying new data centres or expanding aggressively, your deadlines are usually going to be extremely tight. Let’s continue with AWS as they are a perfect case to showcase this point.
In the cloud market, all big players, AWS, Azure and Google cloud (The Top 3) are competing to offer connectivity in as many regions and zones as possible. Faster time to market means you have an advantage over your competitors, and you can offer cloud services when the competition is not yet ready. With automation, you could have a standard Clos design modelled and templated to deploy a complete datacenter in just matter of days. Although this view is overly simplistic, as there are way many pieces than modelling your design, the point I want to make is that automation will help you to reduce your time to market and could give you a valuable advantage over your competition.
Next, you can see a pretty cool map of all the regions and zones on which AWS has a presence on:
In this post, we have seen how automation can help you make your network more consistent and help you to deploy and troubleshoot changes with more confidence. Next, we have seen how to reduce human error by proposing some changes to your workflow, like testing your changes in a dev environment and deploying your changes systematically in favour of manual CLI changes.
To conclude, we have seen how automation can help you scale faster while maintaining high levels of availability and reducing your time to market.
Why do you think Network Automation is important, and how has it helped you?